复习向,Crafting Interpreters
表达式定义 简单起见,算数表达式只包含以下元素:
整数
括号
一元运算符:-
二元运算符:+ - * /
比如-1 + 2*(1 + 3 - 2)
Lexer 第一步将输入表达式分成小单位的token,因为表达式内容较少,只用产出如下组件:
表达式-112 + 2*(1 + 3 - 42) 产出的token序列为-, 112, +, 2, *, (, 1, +, 3, -, 42, ), None
此外增加peek功能,方便后续解析,Lexer如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 class Lexer :def __init__ (self, expr: str ):None def tokens_iter (self ):None for ch in self.expr_str:if ch.isdigit():if num:10 * num + int (ch)else :int (ch)else :if num is not None : yield num None if ch != ' ' : yield ch if num:yield numdef next (self ):"""consume next token and return it None means end of the token stream """ if self.peeked is not None :None else :try :next (self.tokens)except StopIteration:return None return retdef peek (self ):"""peek the next token without consuming it """ if self.peeked is None :next ()return self.peeked
EvalBase 写一个求值的基类,把Lexer组合进去,复用一点代码
class Eval :def __init__ (self, expr: str ):def next (self ):return self.lexer.next ()def peek (self ):return self.lexer.peek()
递归下降
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 class Descent (Eval ):def primary (self ):next ()if isinstance (token, int ):return tokenelif token == '(' :assert ')' == self.next (), 'unbalanced parentheses' return retelse :raise ValueError(f'unrecognized token {token!r} ' )def unary (self ):if token == '-' :next ()return - self.unary()else :return self.primary()def factor (self ):while self.peek() in ('*' , '/' ):next ()if op == '*' :elif op == '/' :else :raise ValueError(f'unrecognized operator {op!r} ' )return leftdef expr (self ):while self.peek() in ('+' , '-' ):next ()if op == '+' :elif op == '-' :else :raise ValueError(f'unrecognized operator {op!r} ' )return leftdef eval (self ):return self.expr()
Pratt方法
代码方面,首先记录运算符的优先级,而递归下降中的类似
from enum import Enumclass Prec (Enum ):def next (self ):"""return the next level precedence Prec.Primary will return itself""" return Prec(min (self.value + 1 , self.Primary.value))def __le__ (self, other: 'Prec' ):return self.value <= other.value
新建一个Pratt类,主要构建出根据token进行分发的函数表格。
加入Prec信息和prec_of,是因为合并了一些逻辑,比如binary的参数token可能横跨两个优先级,需要识别出以继续收集。事实上,如果没有合并,每个收集函数,对自己该继续收集什么层级的表达式,都是清楚的,比如之后会看到的unary直接调用parse_with(Prec::Unary),这也是-在表中只记录它在binary中的优先级的原因。
默认返回的优先级是Null,所以最后的中止token为None,可以用来跳出所有中缀表达式的调用,结束解析
stack用来求值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 @dataclass class DispatchEntry :None None class Pratt (Eval ):def __init__ (self, expr: str ):super ().__init__(expr)'num' : DispatchEntry(self.num, None , Prec.Null),'+' : DispatchEntry(None , self.binary, Prec.Term),'-' : DispatchEntry(self.unary, self.binary, Prec.Term),'*' : DispatchEntry(None , self.binary, Prec.Factor),'/' : DispatchEntry(None , self.binary, Prec.Factor),'(' : DispatchEntry(self.group, None , Prec.Null)def fetch_entry (self, token: str ):if token and isinstance (token, int ):'num' return self.index_map.get(token, EmptyEntry)def prefix_fn_call (self, token: str ):if fn := self.fetch_entry(token).prefix:return fn(token)raise ValueError(f'unkown token to dispatch prefix: {token!r} ' )def infix_fn_call (self, token: str ):if fn := self.fetch_entry(token).infix:return fn(token)raise ValueError(f'unkown token to dispatch infix: {token!r} ' )def prec_of (self, token: str ):return self.fetch_entry(token).prec
然后加入被分配的收集函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 def parse_with (self, prec: Prec ):next ()while prec <= self.prec_of(self.peek()):next ()def unary (self, token: str ):if token == '-' :1 ] = -self.stack[-1 ]def binary (self, token ):next ())if token == '+' :elif token == '-' :elif token == '*' :elif token == '/' :def group (self, token ):assert ')' == self.next (), 'unbalanced parentheses' def num (self, token: int ):def expr (self ):next ())def eval (self ):return self.stack[-1 ]
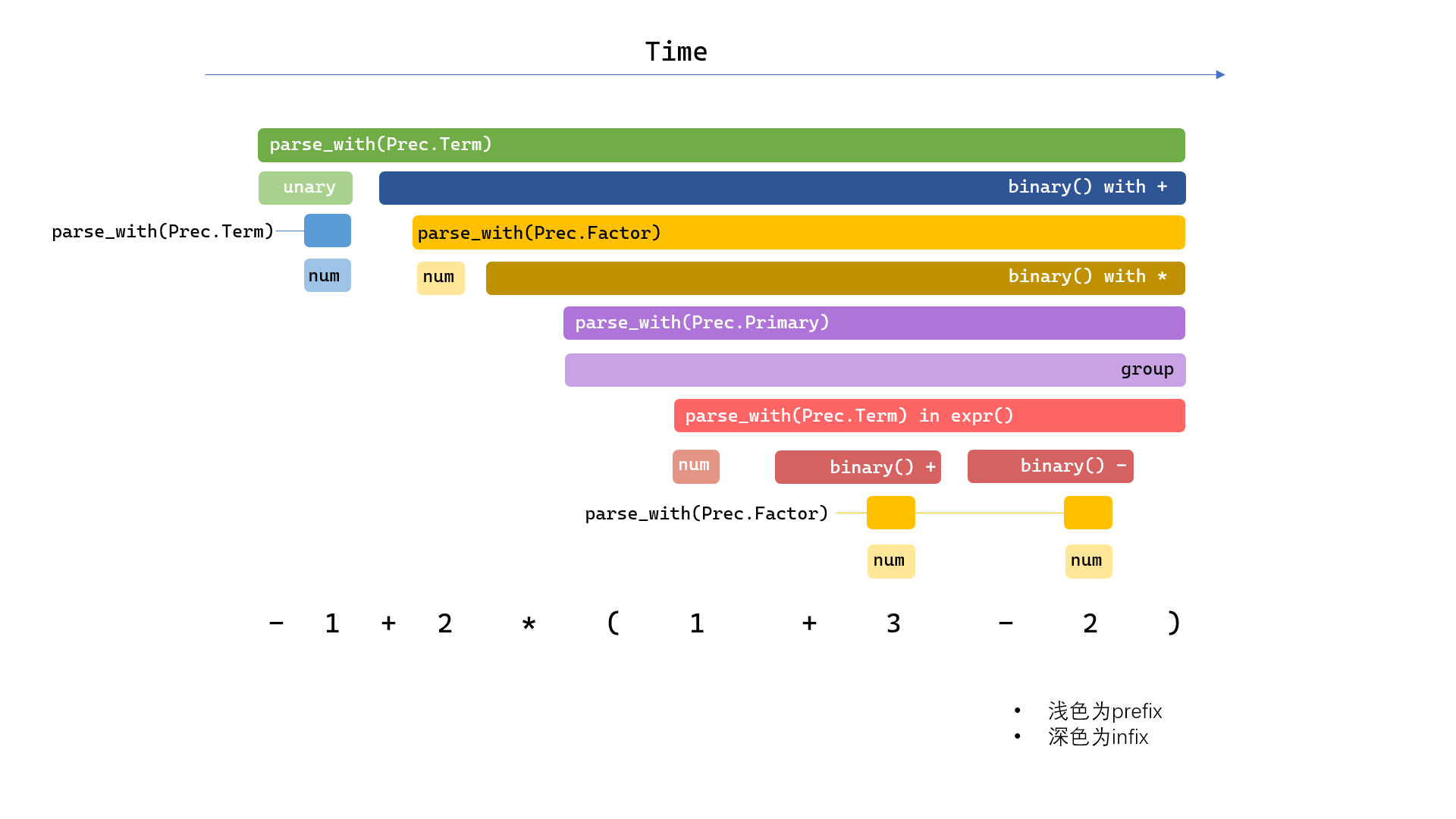
画了一个调用栈来表示解析过程,paser_with都用主色表示,它所引发的prefix调用都用浅色表示,所引发的infix调用使用深色。
结论
递归下降中的规则从上往下,优先级上升,问题规模下降
Pratt方法的核心是parse_with(prec :Prec) { 前缀表达式 (中缀表达式)*}将下一个表示式的值入栈,该值的求解过程中使用的操作数,都大于等于prec优先级
Pratt中的prec_of出现是因为收集函数的逻辑合并
Pratt方法中的最小逻辑用来跳出中缀匹配